Что такое анализ данных поперечного сечения?
Анализ данных в разрезе — это когда вы анализируете набор данных в фиксированный момент времени. Обследования и правительственные отчеты являются некоторыми распространенными источниками данных в разрезе. В наборах данных записываются наблюдения за несколькими переменными в определенный момент времени.
Финансовые аналитики могут, например, захотеть сравнить финансовое положение двух компаний на определенный момент времени. Для этого они сравнили бы балансовые отчеты двух компаний.
Ниже приведены консолидированные балансы Amazon и Apple на конец года. Аналитик может использовать их для оценки их финансового положения за 2018 год. Однако небольшая разница в датах окончания отчетного периода может потребовать внесения некоторых корректировок.
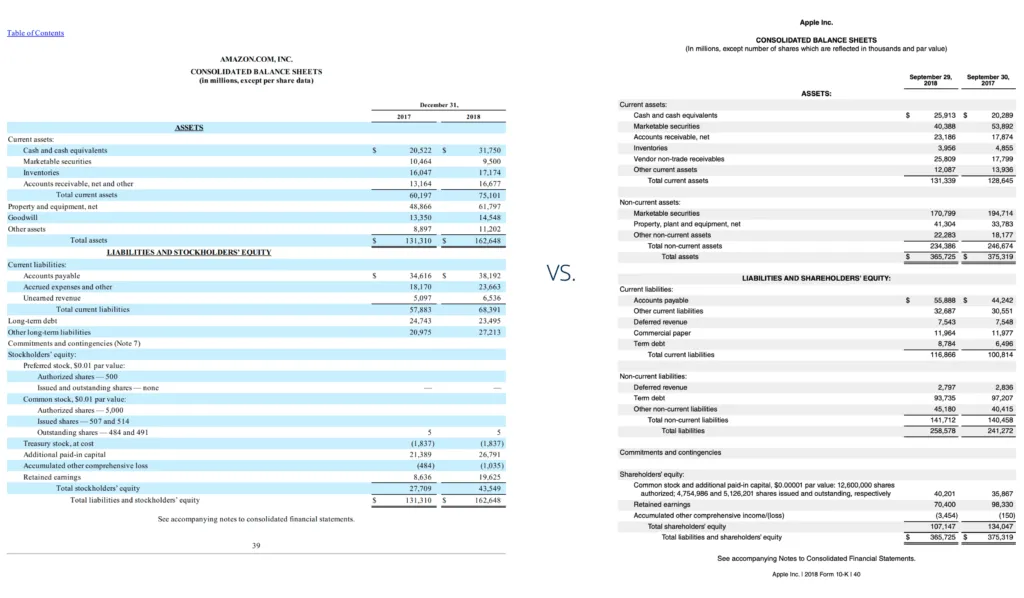
Продвинутый курс финансового моделирования и оценки CFI включает в себя обширное тематическое исследование Amazon.
Примеры наборов данных поперечного сечения включают:
- Валовой внутренний продукт (ВВП) стран Северной Америки в 2012 году – Экономической единицей анализа является страна из Северной Америки. Экономическая единица анализа относится к периоду 2012 года. Типичной записью из набора данных будет (Соединенные Штаты Америки, 16,16 трлн. долл.).
- ВВП на душу населения европейских стран в 2010 году – Экономической единицей анализа является страна из Европы. Экономическая единица анализа относится к периоду 2010 года. Типичная запись из набора данных будет (Германия, 41 700 долл.).
- Общий объем экспорта стали азиатскими странами в 2015 году – Экономической единицей анализа является страна из Азии. Экономическая единица анализа относится к периоду 2015 года. Типичной записью из набора данных будет (Индия, 3,17 миллиарда долларов).
- Общее количество апельсинов, съеденных домохозяйствами в Гане в 2018 году – Экономической единицей анализа является домашнее хозяйство в Гане. Экономическая единица анализа относится к периоду 2018 года. Типичной записью из набора данных было бы (302 домохозяйства, 200 апельсинов).
Использование данных поперечного сечения
Наборы данных поперечного сечения широко используются в экономике и других социальных науках. Прикладная микроэкономика использует наборы данных поперечного сечения для анализа рынков труда, государственных финансов, теории организации промышленности и экономики здравоохранения. Политологи используют данные по разрезам для анализа демографии и избирательных кампаний.
Финансовые аналитики обычно сравнивают финансовую отчетность двух компаний, перекрестный анализ заключается в сравнении отчетности двух компаний на один и тот же момент времени. Сравните это с анализом данных временных рядов, при котором сравниваются финансовые отчеты одной и той же компании за несколько периодов времени.
Источники данных поперечного сечения
- Бюро статистики труда
- Данные переписи
- Обследования населения
- Федеральная резервная система
- Групповое исследование динамики доходов
- Бюро экономического анализа США
- CompuStat
- Банк международных расчетов (BIS)
Случайная выборка
Система случайной выборки — это статистическая структура, которая широко используется при анализе данных. Метод случайной выборки работает в предположении, что существует тесная связь между совокупностью и выборкой, взятой из этой совокупности.
Рассмотрим пример потребления апельсинов домохозяйствами Ганы, описанный выше. Потребуется много ресурсов (как времени, так и денег), чтобы измерить фактическое потребление апельсинов каждым домохозяйством в Гане. Было бы намного дешевле измерять потребление апельсинов только в 1000 домашних хозяйствах в Гане. В таком случае население состоит из каждого домашнего хозяйства в Гане, а выборка состоит из 1000 домашних хозяйств, данные о потреблении апельсинов в которых известны.
Эконометрический анализ наборов данных поперечного сечения обычно предполагает, что данные генерируются независимо и что наблюдения являются взаимонезависимыми. Такое допущение о независимо сгенерированных данных нарушается, когда экономическая единица анализа велика по сравнению с населением.
Предположим, мы хотим проанализировать ВВП всех стран Северной Америки. Наше население, в данном случае, состоит из 23 стран. Любая выборка, которую мы строим из населения, вряд ли может поддерживать построение взаимонезависимой случайной выборки. Например, весьма вероятно, что ВВП Соединенных Штатов коррелирует с ВВП Канады.
Случайная выборка при анализе данных поперечного сечения
Рассмотрим набор данных поперечного сечения, который измеряет K характеристик для N различных экономических субъектов в момент времени t. Отдельное наблюдение в наборе данных поперечного сечения имеет вид:
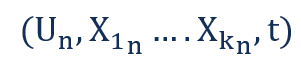
Где:
- Un — это n-я экономическая единица анализа
- X1n является i-й характеристикой для n-й экономической единицы
- t — это время
Набор данных поперечного сечения был создан с использованием случайной выборки, взятой из генеральной совокупности (F, X, t), где F — совместное распределение всех (U, X) в генеральной совокупности в момент времени t.


